
ETL Process and Challenge
Project Overview
The goal of this project is to show my process in preforming ETL on a new dataset and how to find errors we would want to remove before preforming any analysis. This dataset was part of a challenge through SuperDataScience, a platform that teaches data science and business intelligence tools. In this process we will be using a combination of NotePad++, Excel, SSIS, and SQL to try to find errors in the data that would skew our analysis. Note that on Macs the process would be slightly different, NotePad++, SSIS, and SQL are programs that only run on Windows. There are other available solutions like Atom/Brackets as your text editor and PostgreSQL for SQL. I may choose to run this process on a Mac in another post since I also do work with my MacBook Pro.
The dataset is just over 1.05M rows and has 5 errors that we need to try to find. Below is the only info we were given in the challenge.
- The CustomerID field does not contain duplicate records.
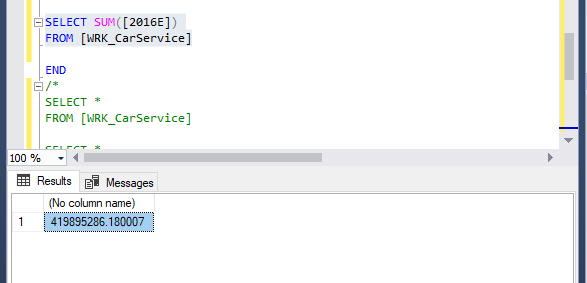
- You know that the total projected revenue for 2016 equals: $419,896,187.87
- Give a small explanation to how the error might of occurred.
Link to GitHub Repo: GitHub
Part I: NotePad++ & Excel
Now to start, the most important thing is to track as much as possible the changes that happen to the original data and always keep a copy of the original data unchanged. This allows us to have options in case we make any mistakes. In my GitHub Repo there is a break down of the way I format the folders in projects. I make a copy of the original data and move it to the Prepared Data folder and work on it only through this folder.
Now opening the data in NotePad++
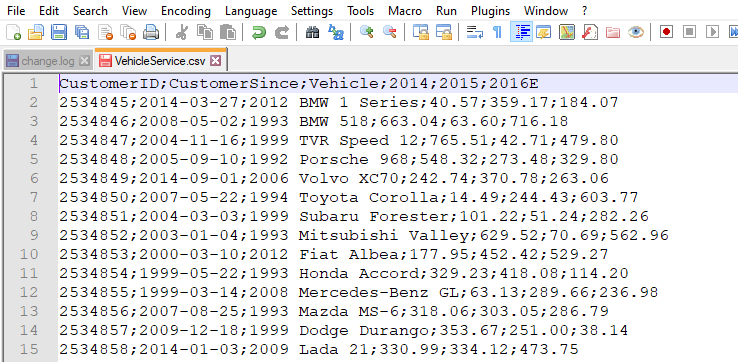
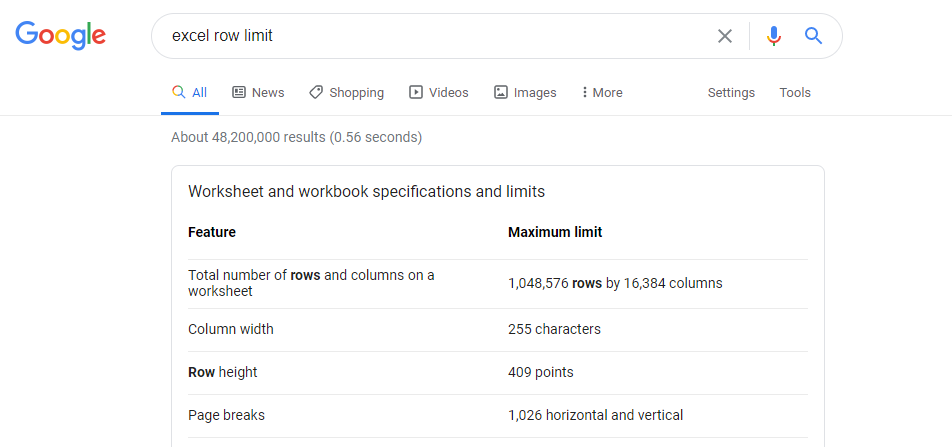
We see that this is a dataset from a car maintenance company. We have three columns, CustomerID, CustomerSince, and Car, that describes the customer and the car serviced while the other three columns are what each customer spent that year. Column 2016E is the projected sales for that year. Below we see that we have 1.05M rows which due to excel’s row limitation, second image, we will need to spilt the data and combine them after we load it into Excel. Also note here that this is a semicolon separated file which is important when loading into Excel.

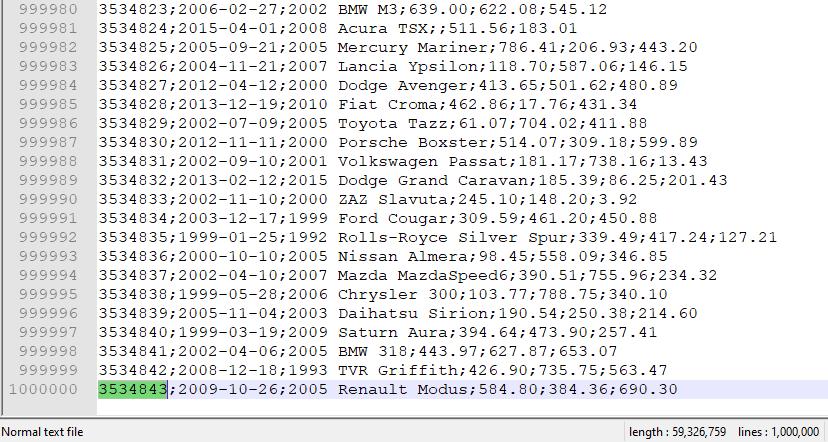
In NotePad++ we use CRTL-G to go to row 1M and cut everything to the bottom. Save this file as ..copy1 and create a new file with the remaining copied rows and name it ..copy2. Now we will preform a check to see that the beginning of ..copy2 is the end of ..copy1. As CustomerID is usually a unique number, will verify this later, we can see that we are good and didn’t accidentally delete something.

Now we move on to Excel. We open our files in an empty Excel sheet to ensure it goes through the Text Import Wizard.
Here we want to put it as delimited, click next.
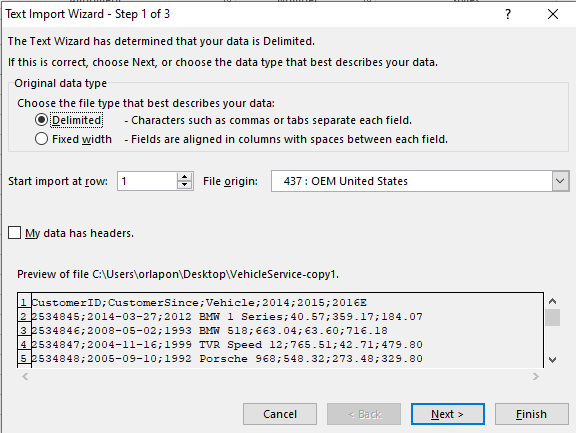
Here we uncheck Tab and check Semicolon as your delimiter. This is why it’s important to know get to know the file before loading.
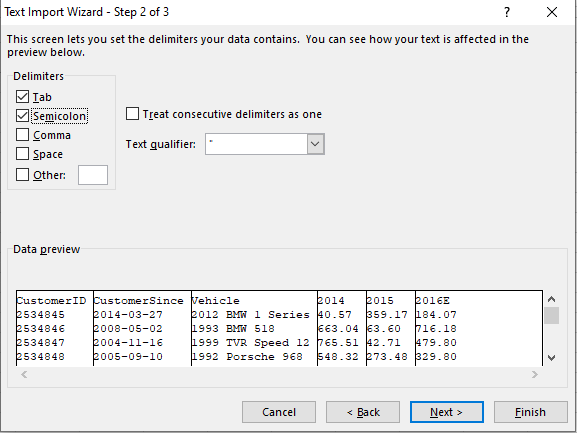
Here we highlight all the columns and switch everything to text. Click Finish.
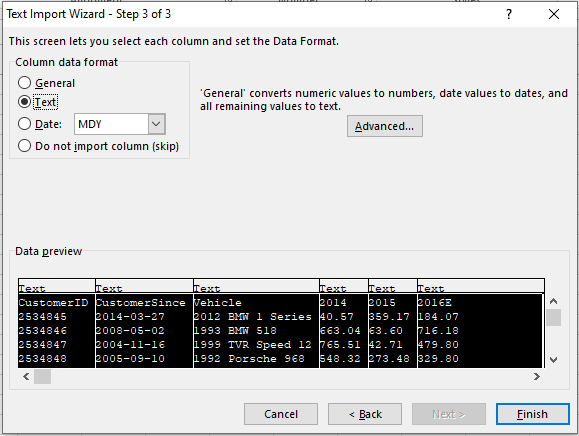
Now that we have the data loaded. We will make sure all the columns are formatted properly, first with the dates. Although already in YYYY-MM-DD format we want to make sure nothing changes when we export the data as a csv file. Using Text to Column in the Data tab below.
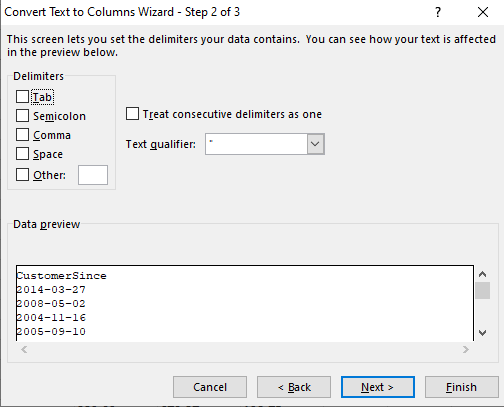
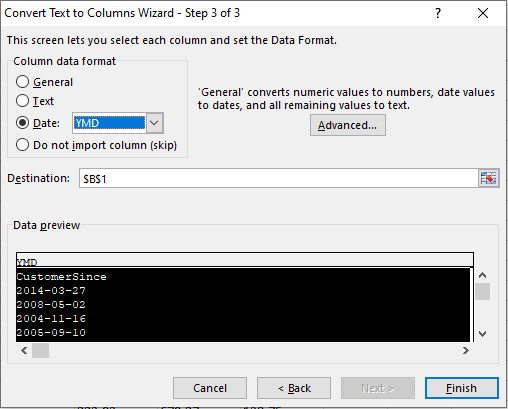
Next we will work on the sales columns. Similar process using Text to Column, convert to number, and fix the first row as text since this is the Year.
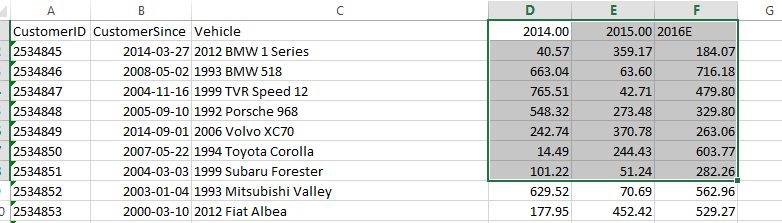
With that the file is ready to be exported as a csv file. We will do the same process above to the ..copy2 file and export that as a csv file. Below we open them both in NotePad++ and merge them together into a new file called ..-Combined.
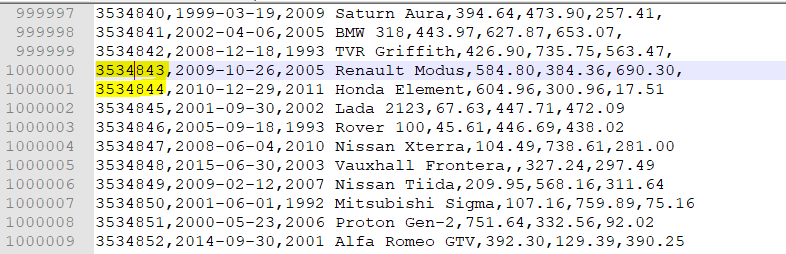
We will take this file and load it up in SSIS next to start checking for any errors in the data. The reason we format it in Excel first is so when we load into SSIS, Excel would have created a new column if there was any issue with a delimiter or a typo in any row. There are other ways to check for this but this has worked for me well.
Part II: SSIS
SSIS is a ETL tool that allows us to find errors in the dataset. SSIS its self is a very versatile tool and can be used for a lot more than what we will be using it for today.
We start by starting a New Project and choosing the Integration Services under the Business Intelligence section. Give it name such as Car Service and click OK.
When it loads up we will be in the Control Flow tab on the top. We will need to drag out a Data Flow Task from the SSIS Toolbox into the Control Flow window. Give it name similar to the project name, you can also give it the date. Click on the Data Flow tab and now we are on the main page where we will be doing most of the work.
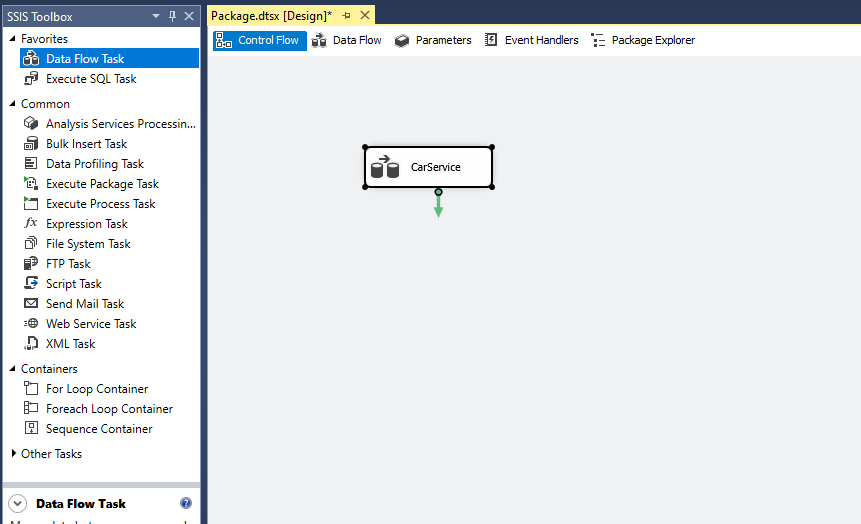
We will need to drag out a Flat File Source from Other Sources. This is how we will be loading the data into SSIS. Next we, in this situation, will drag out the OLE DB Destination which will load the “cleaned” data into MicroSoft SQL. If you wanted a csv file, you can use the Flat File Destination to create that file.
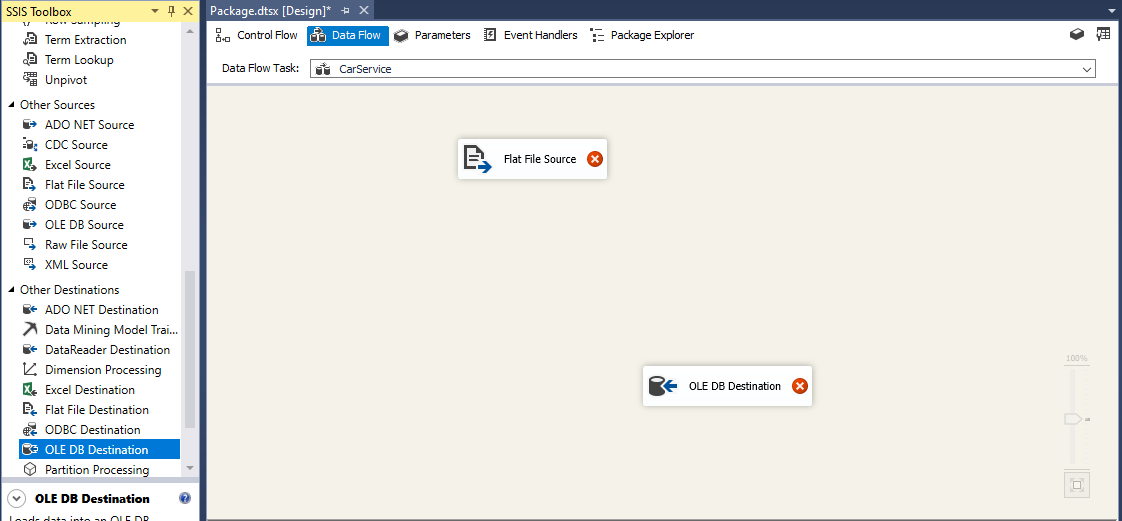
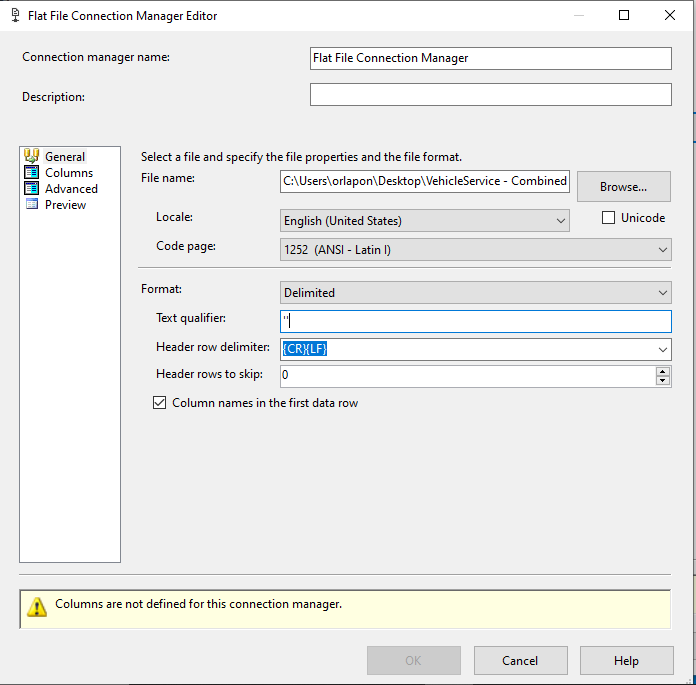
Double-click on the Flat File Source and then click on Browse.. find your ..Combined file to load up. Change the text delimiter to double quotes(“). Next check the columns.
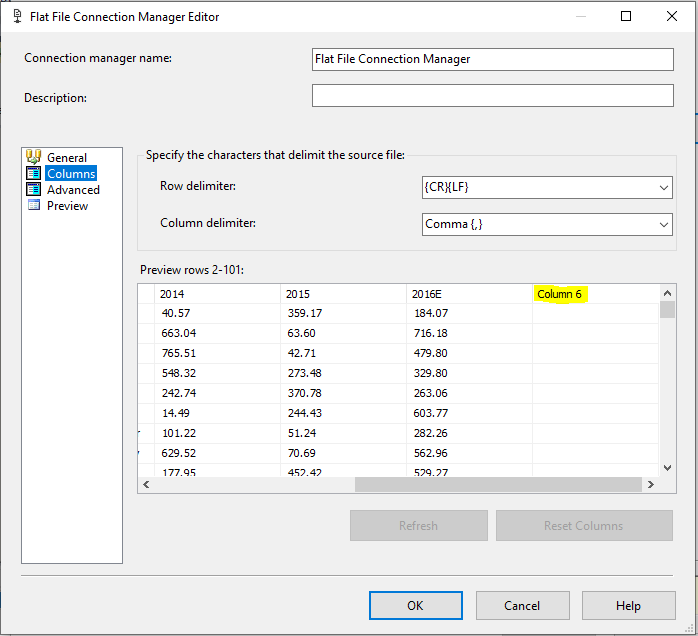
Below we see why it was important to take the data and load it into Excel. Although tedious to most, it allows us to identify any row shifts from errors in the data. Excel helps us ID them by creating this new Column 6 and when we load into SSIS, SSIS will also ID it as a column. We’ve found our first error(s) and next we will use SSIS to exact them from over 1M rows.
Continuing, in the Advance section we will highlight all the Columns and adjust the OutputColumnWidth to something that wont truncate your data and give you errors. 1000 characters in this situation should be just fine, click OK to finish.
Now Flat File Source no longer has a Red X on it so we’re clear to move forward.
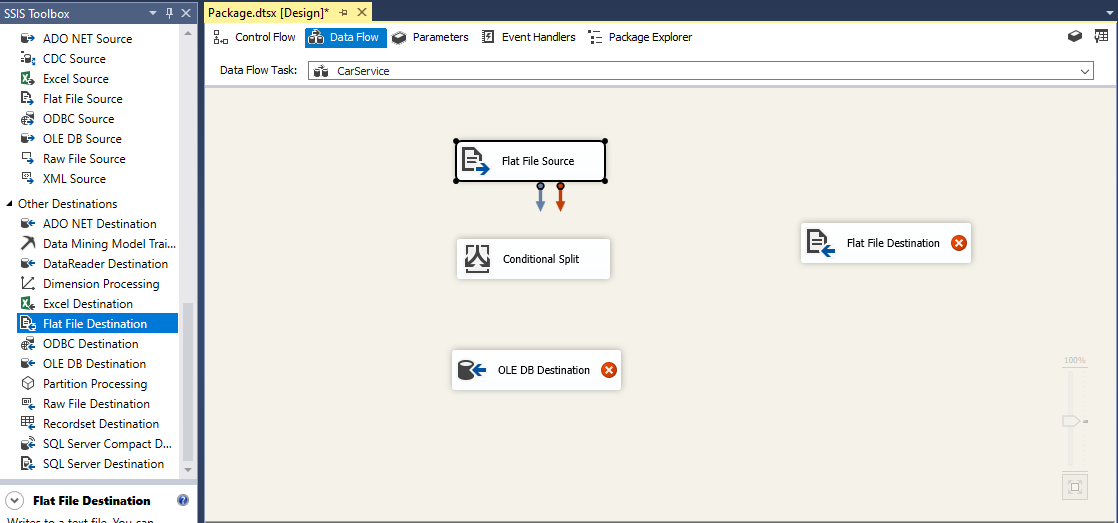
We will take a Conditional Split from SSIS Toolbox and a Flat File Destination for the location to place any error records we find using the Conditional Split. We format the split first.
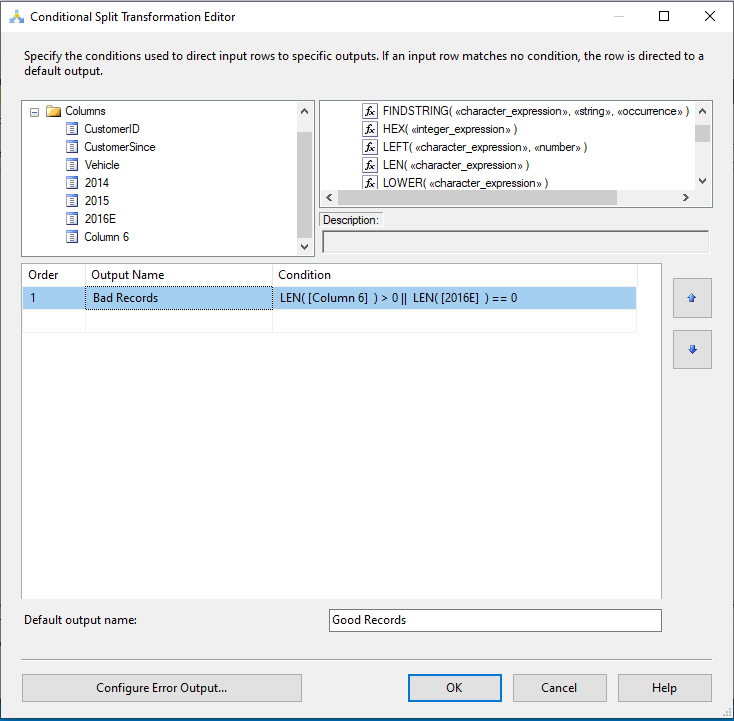
Here in the Conditional Split we will need to logically test how to ID row shifts. We name the Output Name Bad Records and in the condition we will use LEN([Column 6]) > 0 to check the length of all the rows in Column 6, since we shouldn’t have anything in this column anything, or 0, anything not a 1 is an error. Using the logical or, || we will also check for any row shifts to left or in Column 2016E. Here we will use LEN([2016E]) == 0 to check if we have any empty cells in that column. Remember to name the Default Output Name to Good Records. Click OK and we’re done here. Note: If we have any important data that is essential, we would use this same method to make sure it was included in the data.
Setting up the Flat File Destination is similar as before. Click Browse, then here we will create a text File 2020_05_08_BadRecords in a folder for Removed Rows to account for any changes. This file will be where SSIS puts any error rows we may find.
With these all set up, we will drag the blue arrow from the Flat File Source to the Conditional Split. Next we take the Blue Arrow in Conditional split and drag it towards the Flat File Destination, choosing Bad Records as the Output. When we drag the again from Conditional Split to the OLE DB Destination, it will automatically set it to Good Records.
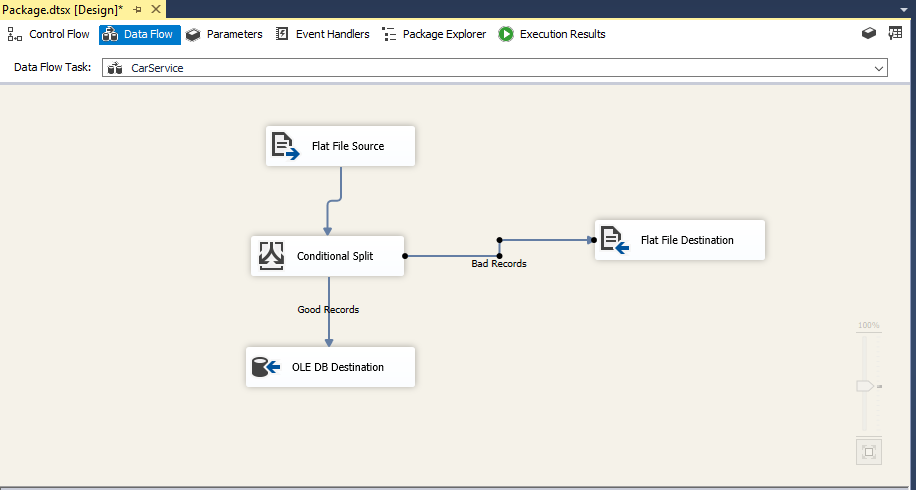
Now we will set up the RAW table in MS SQL by setting up OLE DB Destination and then clicking New to open a SQL script used to create the table. We add [RowNumber] int identity(1,1) to add a new column to track row numbers and change the table name to RAW_CarService.
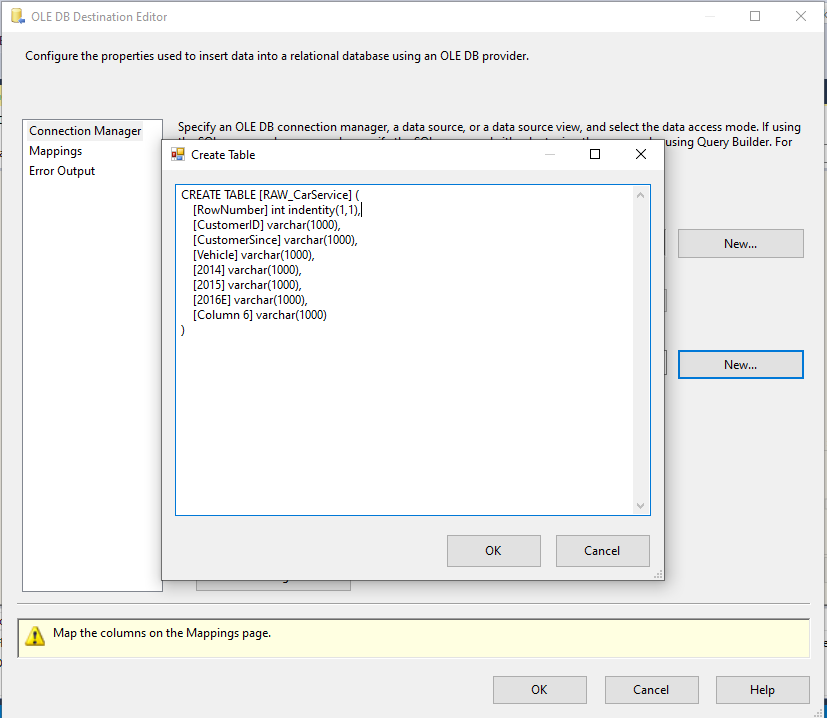
Note: Sometimes we have issues here when setting up the SQL database, usually a Red X or Yellow Sign. To fix this we go into the OLE DB Destination and on the right we switch the AlwaysUseDefault parameter to True.
Once everything is set we press the Execution Results button on the top right to start the process. We should see something similar to the below. This could take some time to run as it is over 1M rows.
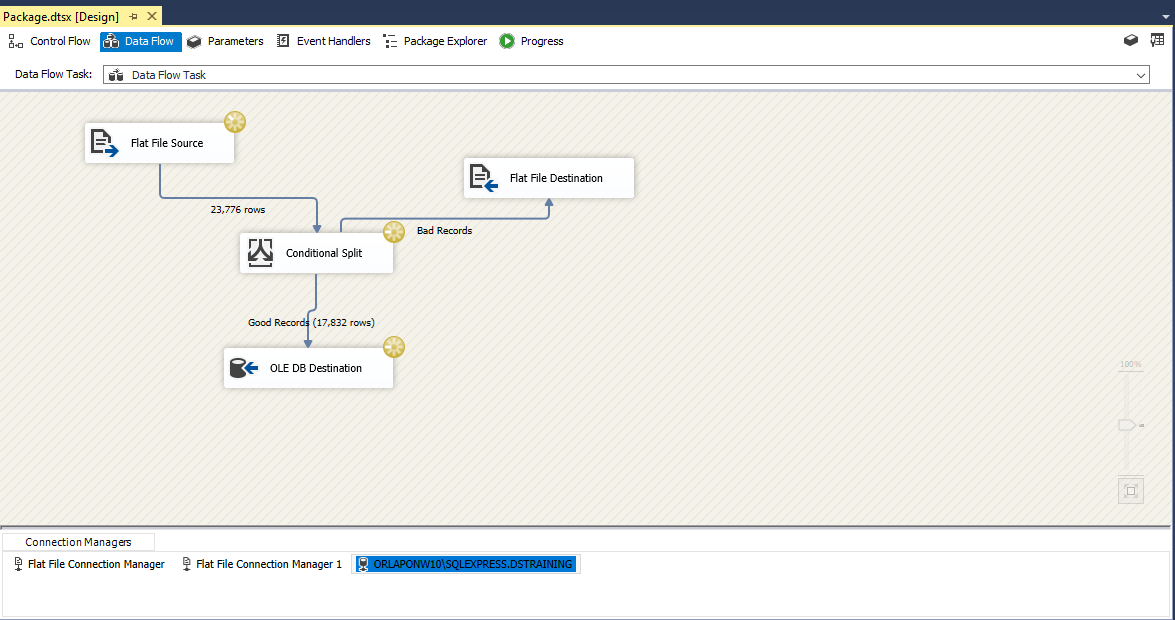
After it finishes we should see something similar to the below. We’ve found 1 Bad Record and loaded into the Text file we set up.
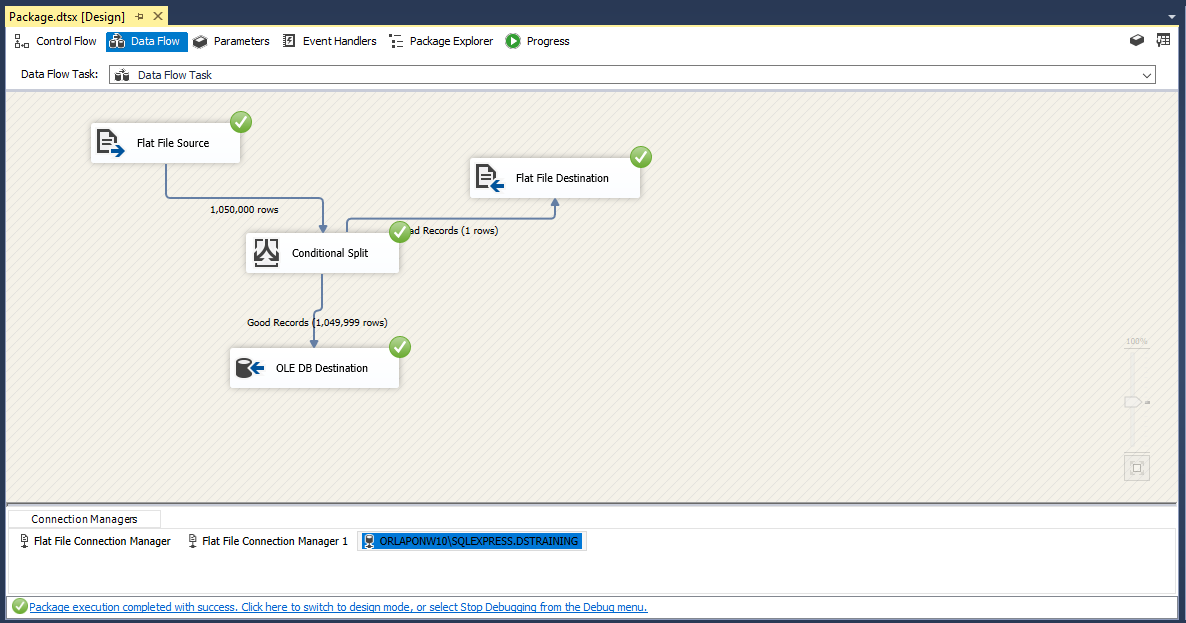
Before we check it in NotePad++ we will go back to the Control Flow tab and right click the Data Flow Task and disable it.
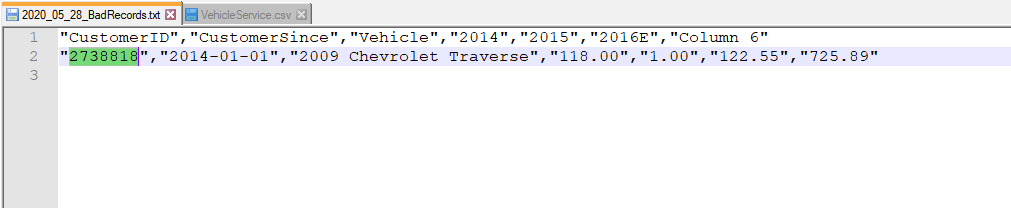
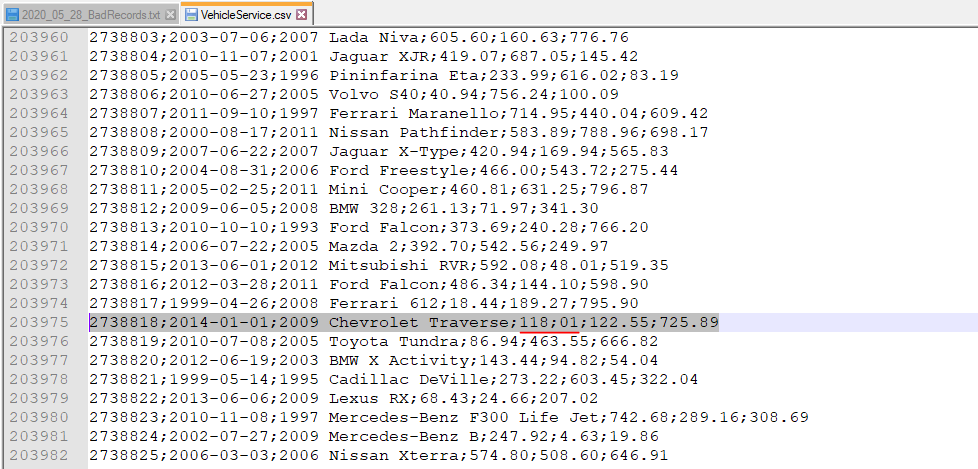
First Error
Using the Bad Record file we can check which row had the error. Going back to the original data we see that the row shift was due to the extra ; in between 118 and 01 making it two separate numbers. There must have been an error in loading the data that caused it to add the extra semicolon.
Part III: MS SQL
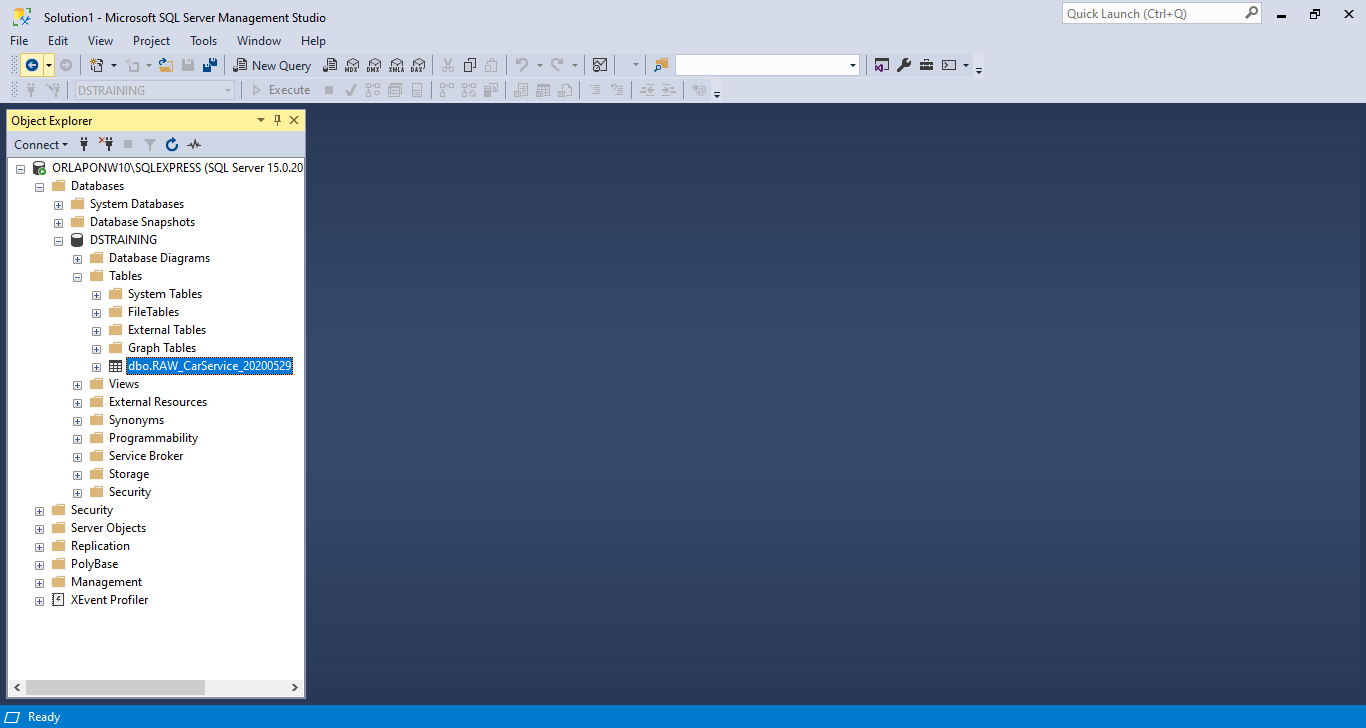
Now we will move over to Microsoft SQL Server Management Studio, open up our database, and check if our RAW table was created from SSIS. As we can see, it was completed correctly.
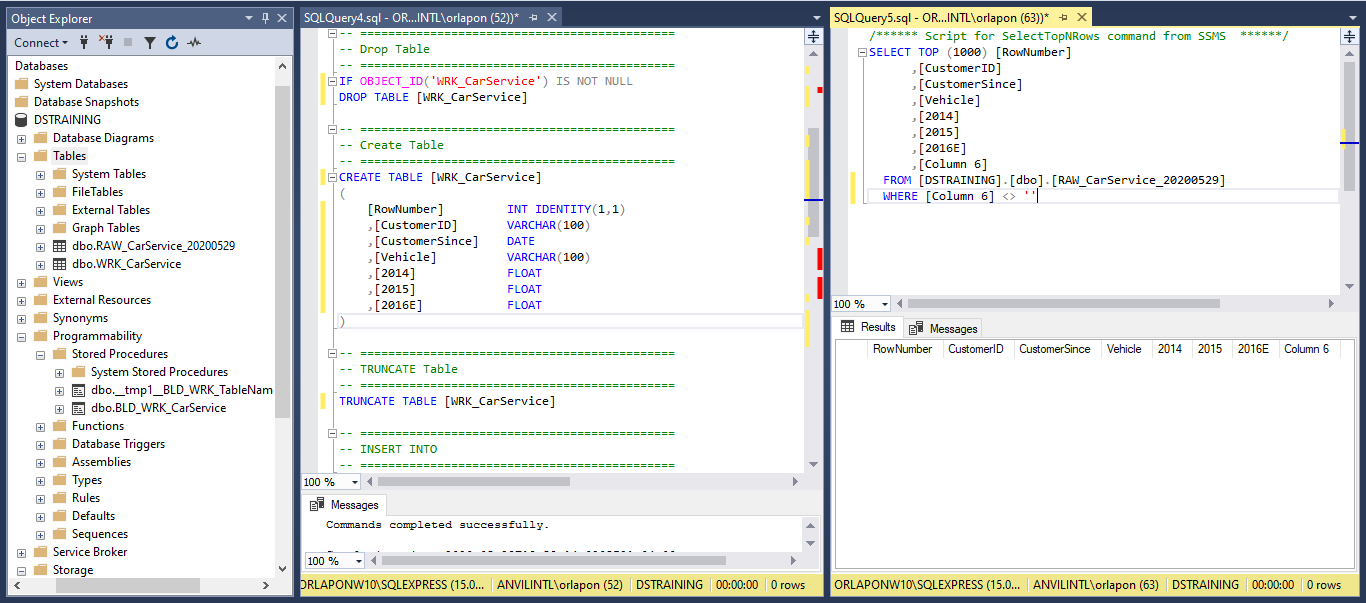
Below is the Stored Procedure template that we will use to convert a RAW table that we created using SSIS. This also allows us to have a record of how we converted the tables.
USE [DSTRAINING]
GO
/****** Object: StoredProcedure [dbo].[__tmp1__BLD_WRK_TableName] Script Date: 5/28/2020 8:22:27 PM ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER PROC [dbo].[__tmp1__BLD_WRK_TableName]
-- =============================================
-- Author:
-- Create date:
-- Description: RAW to WRK Table
-- Modified Date:
-- =============================================
AS
BEGIN
-- =============================================
-- Drop Table
-- =============================================
IF OBJECT_ID('WRK_TableName') IS NOT NULL
DROP TABLE [WRK_TableName]
-- =============================================
-- Create Table
-- =============================================
CREATE TABLE [WRK_TableName]
(
[RowNumber] INT IDENTITY(1,1)
,[AAA] VARCHAR(100)
,[BBB] VARCHAR(1000)
,[CCC] DATE
,[DDD] INT
,[EEE] FLOAT
)
-- =============================================
-- TRUNCATE Table
-- =============================================
TRUNCATE TABLE [WRK_TableName]
-- =============================================
-- INSERT INTO
-- =============================================
INSERT INTO [WRK_TableName]
(
[AAA]
,[BBB]
,[CCC]
,[DDD]
,[EEE]
)
SELECT
[xAAA]
,[xBBB]
FROM [RAW_TableName]
--(x row(s) affected)
END
Below we replaced the TableName, add our author info, and start the process of creating the shell of the WRK table. In the CREATE TABLE section we will add the Column names and the column data type. VARCHAR for text, DATE for the dates, and float for the year’s sales numbers. Note that in the far right window we are performing a test to check that we have an empty column for [Column 6]. Beautiful, moving forward.
Here we will use INSERT INTO to move the data in the RAW table to the newly made WRK table. Since we set up the data types in the CREATE TABLE section through implicit conversion we will not need to add them here. Run the code and we get our second error.
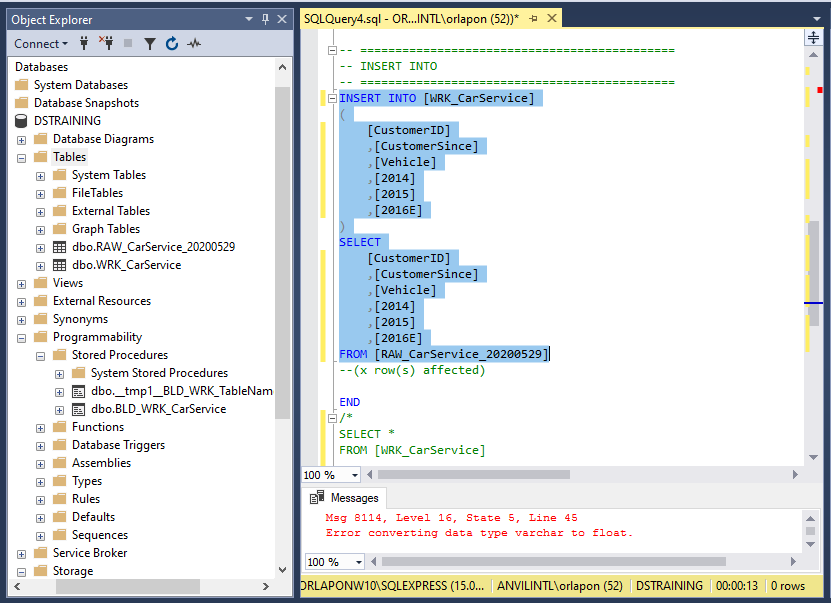
Second Error
Here we got the error message Error converting data type varchar to float. This is the benefit of starting with a RAW table and converting into a WRK. Because of the implicit conversion, if we try to add data that doesn’t conform to the data type we selected it will give us an error. Since the error was for the Floats we only have to check the 2014, 2015, and 2016E columns.
Below we start by opening a new query window and trying to find the error at each column. The first part of the SQL code below is checking that all the data in Column 2014 is a number,isnumeric(), if it’s false we get a 0 meaning there’s a string somewhere. The second portion filters the rows that have empty cell since those wouldn’t be real errors.
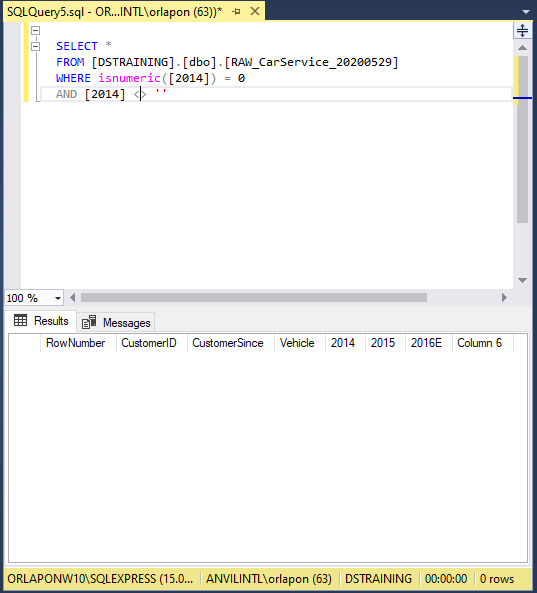
Checking 2015 column we see the error. Somehow when the original data was created there was an $ entered instead of a . for the sales number. Checking column 2016E we see this row is error free.
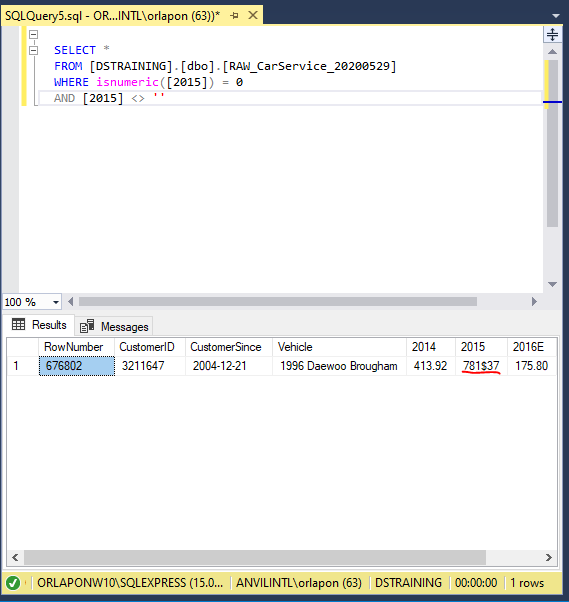
We will fix this issue by excluding this whole row from being inserted into the new WRK table. We do this by adding a WHERE condition to the end of the INSERT INTO section. By flipping the logic from our test code we will exclude this row.
...
)
SELECT
[CustomerID]
,[CustomerSince]
,[Vehicle]
,[2014]
,[2015]
,[2016E]
FROM [RAW_CarService_20200529]
---EXCLUSION
WHERE ISNUMERIC([2015]) = 1
OR [2015] = ''
--(1409998 row(s) affected)
Part IV: MS SQL Continued
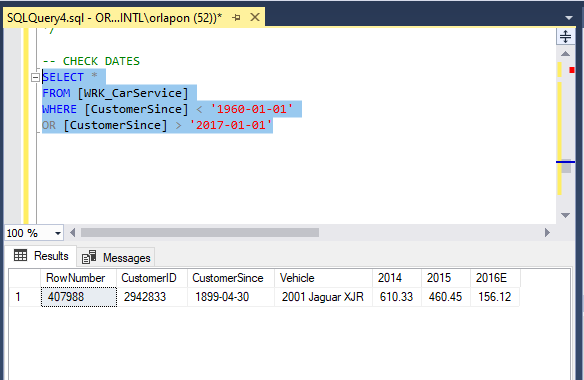
Next we can check for any date errors. We do this by thinking a little bit about the business. How old do you think this company would hold on to its records? How old could this company be? Older than 50, 60 years? These are just things we may have to check. I’m making an assumption that this company can’t have data older than 1965. Second portion of the code checks that there aren’t date issues for the future, in this case past 2016. Here we see our 3rd Error.
Third Error
This one seems to be a typo error as well, meaning to enter 1999 instead of 1899. Unless this company was servicing horse and buggies!?!
Next let’s check if we truly have unique numbers for CustomerID. We do this by using the COUNT() function to create a new column counting the number of CustomerID grouping by CustomerID and only pulling the rows where COUNT is greater than 1 so any duplicates.
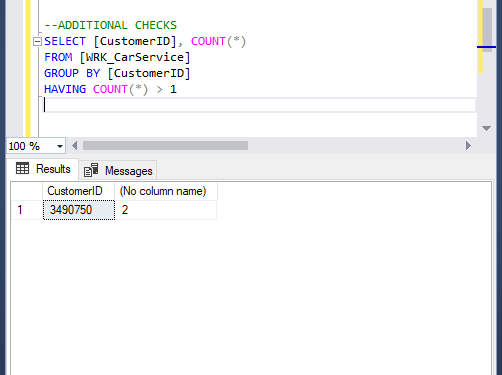
Fourth Error
Here we see that we have 2 duplicate CustomerID. Taking it further, we can use the CustomerID 3490750 to check what happened at these rows. As we can see, there was an error in creating the CustomerID as the rest of the data seems to indicate two separate customers.
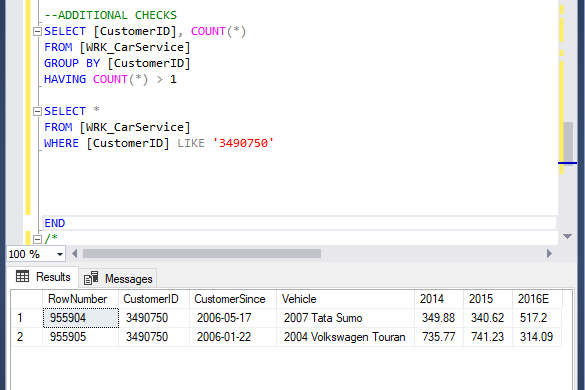
Fifth Error
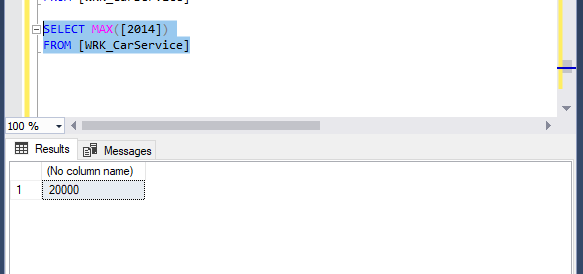
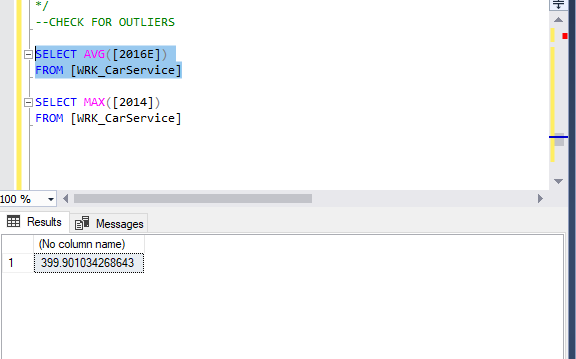
For the last error we did a couple different check. I looked at average, min, and max for the sales columns. We find our final problem by seeing that most of the column averages were around 300 and 2015/2016E maxes were in the similar 300-400 range. 2014 max however has a max of 2000 which is a major outlier in this dataset.
Finally we will preform the final sum check. Adding up all the 2016E and making sure it match what we received in the beginning of this challenge. In order to do so we will gather the excluded rows and get the current total of the 2016E from SQL. Using Excel to see if everything adds up and does!
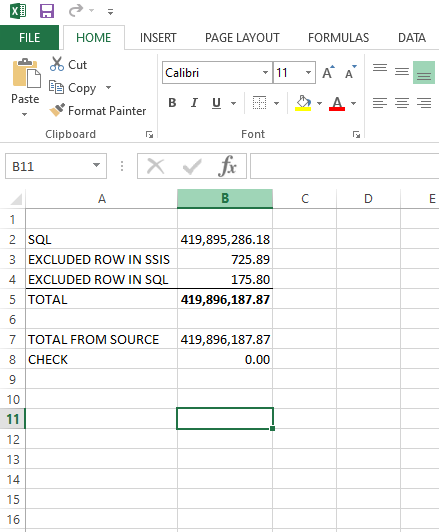
Final Thoughts
Many data science websites, bloggers, and teachers say that data processing and cleaning can be take up to 50-80 percent of your time on a project. Meaning these tools and skills can be the most important part and ensures reliability in the conclusions we make in our analysis. As I do more projects, I can attest to the fact that most models can be reused. One can use a template to get most of the model up and running in a relatively short amount of time. Total, without the 30 plus minute SSIS conditional split, it took us about 45 minutes to just find five errors in this challenge. One can only imagine Big Data datasets that can have billions of rows…I think I would need a couple computers, or maybe a GPU on AWS?